Studierende finden Antworten mit KI
Wie findet man unter den zahlreichen Publikationen und Forschungsbereichen der ETH Zürich das, was man sucht? Um diese Frage zu beantworten, haben sich ETH-Mitarbeitende mit Studierenden des Masterstudiengangs Data Science zusammengetan.
Innerhalb des ETH-Bereichs nach Informationen zu suchen, ist ein gewaltiges Unterfangen. Nebst unzähligen Websites von Departementen, Einheiten und Forschungsgruppen, die alle unabhängig voneinander verwaltet werden, umfasst er auch Informationsdatenbanken wie die Research Collection, ein Repositorium für Publikationen und Forschungsdaten mit mehr als 20’000 Papers, die von Forschenden der ETH Zürich verfasst wurden. Wie können Website-Besucher diese Fülle an Informationen erfolgreich durchsuchen?
Diese Frage stellten sich Paul Cross, Christine Khammash und Christian Schär. Cross arbeitet im Bereich Institutional Research, Khammash ist Teil des Webteams der Hochschulkommunikation und Schär ist im Bereich Software Services der Informatikdienste der ETH Zürich tätig. Im Rahmen eines grösseren Projekts zur Verbesserung der Hochschulwebsite wurden sie beauftragt, die Suchfunktion zu überdenken.
Keine einfache Aufgabe: «Unsere Inhalte und Datenbanken sind sehr dezentralisiert», erklärt Khammash. «Es ist eine Herausforderung, Suchergebnisse zu liefern, die den Erwartungen der User entsprechen.» Cross, der aus dem Bereich Datenmanagement kommt, schlug vor, die enorme Menge an Informationen mithilfe von Datenwissenschaft und maschinellem Lernen zu konsolidieren. «Wir wollten prüfen, wie wir die Informationen mit Hilfe von künstlicher Intelligenz zugänglicher machen können – und wo findet man besser entsprechende Expertise als bei den Forschenden der ETH Zürich selbst?», sagt er.

Die richtigen Expertinnen und Experten für diese Aufgabe fand das Team in einem der Unterrichtsräume des Departements Informatik: die Data-Science-Masterstudierenden Daniel Garellick, Giulia Lanzillotta und Andreas Opedal. Sie übernahmen das Projekt im Rahmen des Data Science Lab, eines Kurses, in dem angehende Datenwissenschaftlerinnen und -wissenschaftler an einem realen Data-Science-Problem aus der Industrie, der Wissenschaft oder dem öffentlichen Sektor arbeiten. Die drei Studierenden entschieden sich für das KI-Suchprojekt, weil es gleich mehrere interessante Bereiche kombinierte, von Big Data über maschinelles Lernen bis hin zur Verarbeitung natürlicher Sprache. «Es war auch schön, einen Beitrag für die ETH zu leisten», schmunzelt Opedal.
Die Tücken des Topic Modelling
Ein zentrales Problem der Suchfunktion ist die konzeptionelle Lücke zwischen den Informationen auf der Website der ETH Zürich und den Suchanfragen, welche die Besucher der Website in die Suchleiste eingeben. «Um diese Lücke zu überbrücken, haben wir Topic Modelling und Embeddings verwendet, um eine zusätzliche Schicht zwischen den Daten und der Suchanfrage zu schaffen. Diese Schicht erfasst die Konzepte in den Informationen und gruppiert sie basierend auf diesen Konzepten», sagt Lanzillotta. So liefert das System bei der Suche nach einem Forschungsgebiet, wie zum Beispiel nach maschinellem Lernen, eine Liste der relevantesten Publikationen dazu, identifiziert ETH-Expertinnen und -Experten auf diesem Gebiet und schlägt sogar verwandte Bereiche vor, wie etwa künstliche Intelligenz. Tippt man den Namen einer Professorin ein, wird angezeigt, zu welchem Departement oder Gruppe sie gehört, welches ihre neuesten Publikationen sind und mit wem sie am häufigsten zusammenarbeitet – Informationen, die die aktuelle Suche nicht liefern kann.
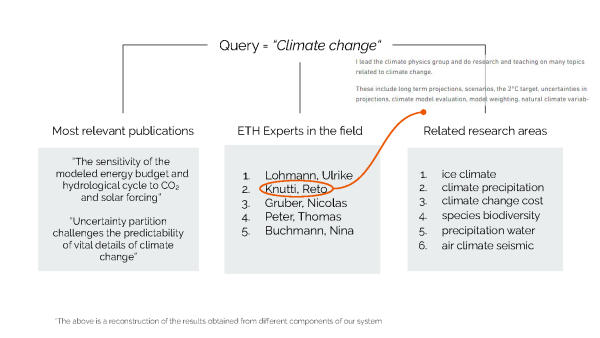
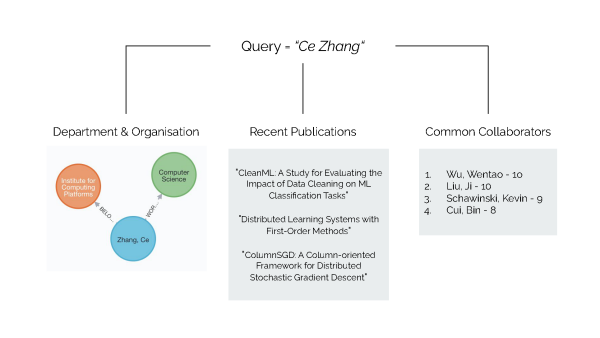
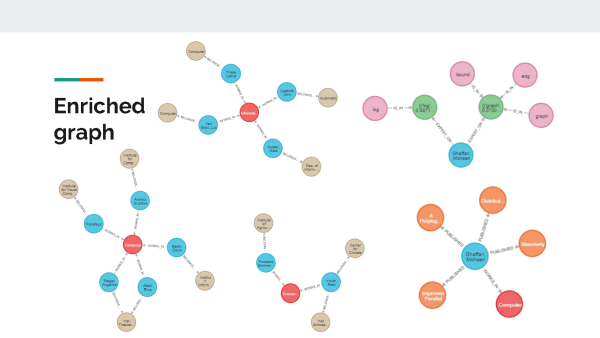
Die Studierenden erzielten ihre Ergebnisse durch eine geschickte Kombination verschiedener Data-Science- und Machine-Learning-Verfahren. Zunächst verwendeten sie eine Technik namens Topic Modelling (Themenmodellierung), um automatisch Themen aus den Abstracts der Publikationen in der Research Collection zu extrahieren. «Wenn sich zum Beispiel ein Paper mit dem Klimawandel beschäftigt, würde unser Modell das identifizieren», erklärt Garellick. Der Output dieses Modells wurde in eine Graph-Datenbank eingefügt, die Verbindungen innerhalb der Informationen speichert; zum Beispiel die Verknüpfung von Forschenden mit ihren Forschungsgebieten, ihren veröffentlichten Arbeiten und ihrem Departement oder ihrer Gruppe. Dann setzten die Studierenden ein Werkzeug namens Embedding Space ein, um alle Publikationen, Personen, Themen und andere Elemente als Vektoren darzustellen. So lassen sich die Informationen leicht verarbeiten, und es können Berechnungen durchgeführt werden, zum Beispiel ein mathematischer Vergleich verschiedener Papers.
Insbesondere ein Modell, das Embedded Topic Model, stellte das Trio in der ersten Experimentierphase des Projekts vor eine Herausforderung. «Wir hatten grosse Hoffnungen für dieses Modell, aber es versagte immer wieder», erinnert sich Lanzillotta. «An einem Punkt extrahierte es unerklärlicherweise gewaltbezogene Themen aus der Research Collection. Das war sehr entmutigend.» Doch dieser Rückschlag lenkte die Studierenden schliesslich auf den richtigen Weg. «Er zwang uns, das Problem anders anzugehen und Elemente aus verschiedenen Bereichen der Datenwissenschaft zu kombinieren, anstatt alles auf ein einziges Modell zu setzen», erklärt Garellick. Opedal fügt hinzu: «Wir haben gelernt, dass es keine Rolle spielt, wie komplex ein Modell ist oder wie viele hochmoderne Features es hat – wenn es nicht funktioniert, sollte man es nicht verwenden.»
«Wir haben gelernt, dass es keine Rolle spielt, wie komplex ein Modell ist oder wie viele hochmoderne Features es hat – wenn es nicht funktioniert, sollte man es nicht verwenden.»Andreas Opedal, Masterstudent Data Science
Im zweiten Jahr ihres Masterstudiums fühlten sich die Studierenden gut gerüstet, um solche Herausforderungen zu meistern. «Wir hatten solides Grundwissen, aber auch die Möglichkeit, mehr zu lernen», sagt Opedal. «Ausserdem haben wir nützliche Soft Skills erworben, wie z. B. das Extrahieren von Informationen aus der wissenschaftlichen Literatur und die Beurteilung der Relevanz der verschiedenen Modelle für unsere Ziele», ergänzt Garellick. Alle drei haben einen unterschiedlichen ingenieurwissenschaftlichen Hintergrund – Lanzillotta ist Informatikerin und Ingenieurin, Opedal hat Wirtschaftsingenieurwesen und Management studiert, und Garellick kommt aus dem Maschinenbau – und waren schon vor dem Projekt befreundet, was ihnen eine effiziente Zusammenarbeit ermöglichte. «Wir passten zusammen wie die Teile eines Puzzles», sagt Opedal. Durch ihre Vorerfahrungen aus Praktika und Jobs waren sie zudem mit Projektarbeit in der Praxis vertraut.
Professionelle Beratung durch Studierende
Die Effizienz und das Fachwissen des Studierendenteams entgingen den Projektverantwortlichen nicht. «Die Studierenden brachten nicht nur viel Data-Science-Kompetenz und neue Ideen in das Projekt ein, sie verhielten sich auch wie professionelle Consultants», sagt Cross. «Besonders beeindruckt hat mich, dass sie eine Liste mit unseren Prioritäten aus der ersten Projektpräsentation verwendet haben, um während des gesamten Projekts auf Kurs zu bleiben.» Khammash hat zum ersten Mal mit Studierenden gearbeitet, aber sicher nicht zum letzten Mal. «Sie waren professionell, sachkundig und fokussiert, und sie brauchten kaum Führung von uns», sagt sie. «Es wäre eine Verschwendung, diese Ressource nicht zu nutzen.»
Khammash und Cross schätzten auch die Unterstützung von Professor Ce Zhang vom Data Science Lab, der sowohl den Projektleitenden als auch den Studierenden beratend zur Seite stand. «Das Suchprojekt ist bestens für das Data Science Lab geeignet, da es seinen Ursprung in einem aufkommenden realen Problem hat», sagt Zhang, der die Forschungsgruppe Data Sciences, Data Systems, and Data Services (DS3Lab) am Departement Informatik leitet. «Wir sind immer wieder beeindruckt, wie gut die Studierenden in diesem Kurs arbeiten, und das Suchprojekt ist keine Ausnahme.»
«Die Studierenden waren professionell, sachkundig und fokussiert, und sie brauchten kaum Führung von uns. Es wäre eine Verschwendung, diese Ressource nicht zu nutzen.»Christine Khammash, Hochschulkommunikation
Opedal, Lanzillotta und Garellick schätzten ihrerseits die Unterstützung von Zhang und den Projektleitenden sowie die von Tarun Chadha, Datenwissenschaftler bei den Scientific IT Services, der das Projektteam begleitete. Der breite Ansatz des Projekts erlaubte es den Studierenden, erfinderisch zu sein und ihre Vorgehensweise frei zu wählen. «Dabei haben uns Paul, Christine und Tarun in die richtige Richtung gelenkt und uns, wenn nötig, auf den Boden der Tatsachen zurückgeholt», sagt Garellick.
Da die Arbeit der Studierenden explorativ war, wird es noch eine Weile dauern, bis künstliche Intelligenz den Nutzern der ETH-Website hilft, das Gesuchte zu finden. «Ich bin etwas erleichtert», gibt Lanzillotta zu. «Ich würde mich sonst für jede einzelne Suche verantwortlich fühlen!» Das Projektteam plant jedoch, die Ideen der Studierenden weiterzuverfolgen und gegebenenfalls mehr Projekte mit dem Data Science Lab durchzuführen. «Obwohl es viel Arbeit ist, den Studierenden die richtige Art und Qualität von Daten zur Verfügung zu stellen, würden wir Kolleginnen und Kollegen an der gesamten ETH Zürich und darüber hinaus die Teilnahme an einem Data-Science-Lab-Projekt sehr empfehlen», sagt Cross. «Es ist eine effektive und dankbare Möglichkeit, reale Herausforderungen mit motivierten, kompetenten und professionellen Data-Science-Expertinnen und -Experten zu erforschen.»
Masterstudium in Data Science

Computer haben die Art und Weise der Produktion, Verwaltung, Aufbereitung und Analyse von Daten grundlegend verändert. Angesichts des kontinuierlichen Wachstums von Daten rund um den Globus ist die Frage, wie wir aus Daten wertvolle Erkenntnisse ziehen und so einen Mehrwert gewinnen können, wichtiger denn je. Wie können Experten riesige Datenmengen erforschen und daraus relevante Informationen herausfiltern? Wie können Computer aus Erfahrungen lernen und mithilfe von Daten intelligente Entscheidungen fällen? Diese Fragen bilden das Fundament des spezialisierten Masters in Data Science, der gemeinsam von den Departementen Mathematik (D-MATH), Informationstechnologie und Elektrotechnik (D-ITET) und Informatik (D-INFK) angeboten wird.