Saving lives with Artificial Intelligence
Doctoral student Fabian Laumer and his colleagues are using machine learning to develop new personalised 3D models of the beating human heart. Their objective is to assist clinicians and improve the diagnosis and treatment of cardiovascular diseases, the most prevalent cause of deaths worldwide.
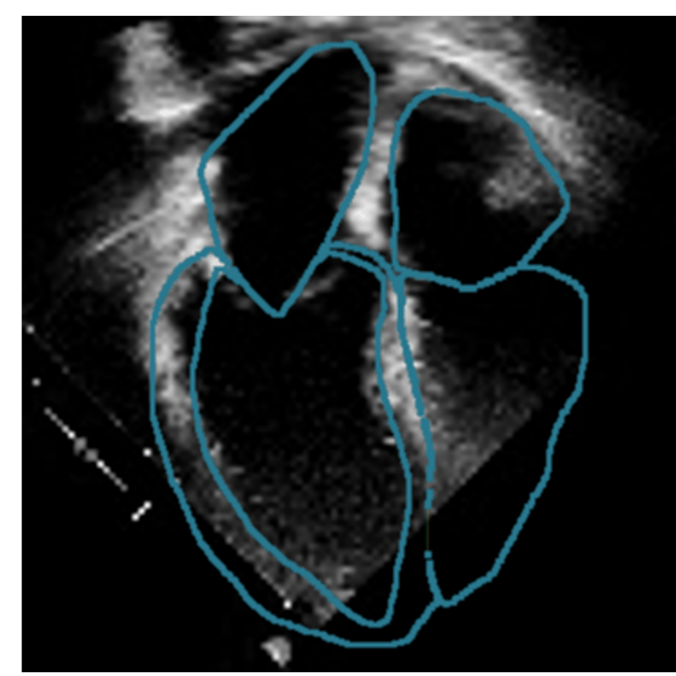
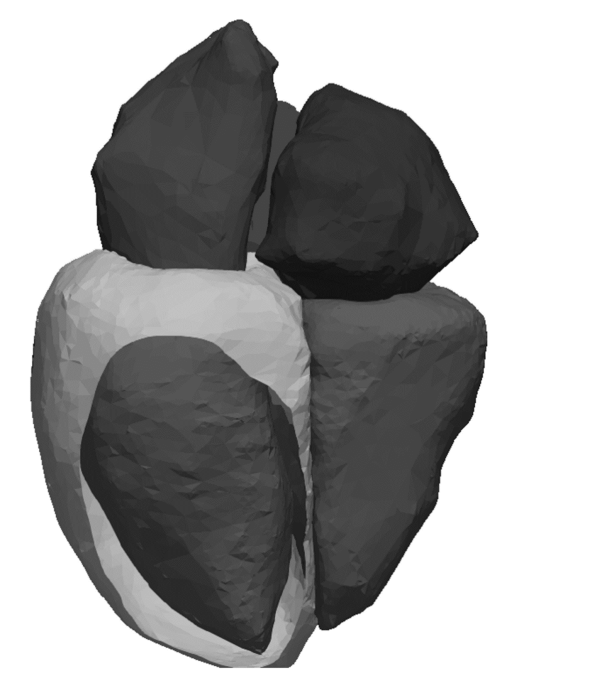
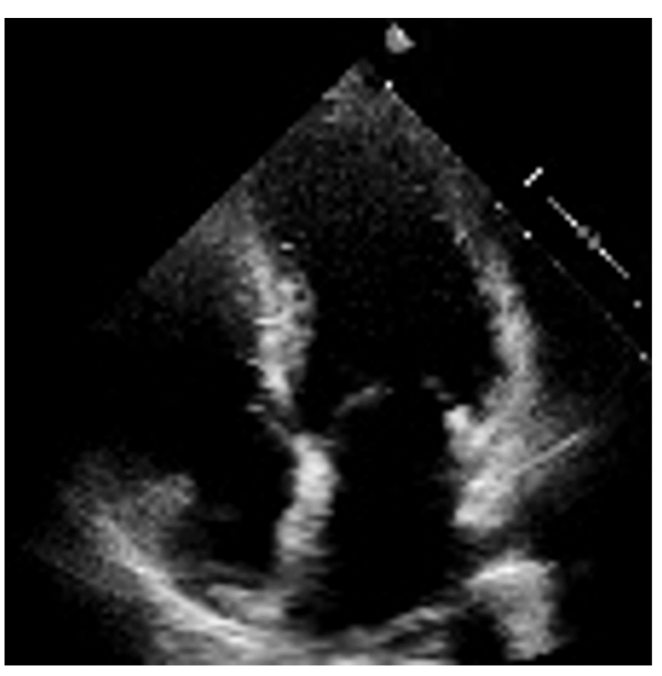
When a patient arrives at a hospital showing signs of a heart attack, doctors measure various parameters to assess the seriousness of the symptoms and define a treatment strategy. One of them, the “left ventricular ejection fraction”, is a measure of the efficiency of the heart and helps predict the evolution of the pathology or the chances of a relapse. “After a first cardiac event,” Fabian Laumer explains, “a less efficient heart correlates with an earlier death. However, these parameters are laborious to measure and not always accurate.”
Fabian Laumer is a doctoral student in the Information and Science Engineering Group of Professor Buhmann, where he is designing machine learning tools to model human hearts. During his Master’s thesis, he developed an algorithm to help cardiologists tell the difference between a heart attack and other types of heart failures. Today, he is working on a framework that will help clinicians in the early diagnosis of cardiovascular diseases using automated assessment of cardiac morphology.
Models of the heart for clinical practice
3D models of the heart are nothing new, but the existing ones are based on Magnetic Resonance Imaging (MRI) or Computed Tomography (CT). These are very expensive imaging techniques; they are uncomfortable at best for patients and not routinely performed. In contrast, echocardiography is relatively inexpensive, non-invasive and is carried out systematically. Using 2D echocardiography videos, Fabian is working on developing a new AI framework that creates a four-dimensional representation of a patient’s heart shape (3D video). From this, it is straightforward to mathematically extract a wide range of parameters, including but not limited to the left ventricular ejection fraction. This automation of cardiac measurements facilitates the work of clinicians when generating examination reports and will hopefully help in defining the best treatment strategy for each patient.
Another promising benefit of the model is to identify new features of the heart’s shape and movements that could predict certain pathologies or be associated with given outcomes, such as the likelihood of complications or death within the next few months.
The challenges of using machine learning with medical data
But deriving an accurate personalised representation of a patient’s heart is more complicated than it sounds. Despite great advances in machine learning in recent years, only very few applications are being successfully brought into the medical world. This is not solely due to the very real challenges of collecting patient data and navigating ethical issues associated with using technology in the medical domain. There are major technical difficulties that are inherent to medical data as well. One of them is heterogeneity: The quality of the data varies greatly depending on who has acquired it, on the patient or even on the imaging machine with which it was acquired. In the case of echocardiography, some videos are shorter, longer or focus on different parts of the heart. Some are more “zoomed-in” (or out), have a lot of noise or have even been made in the ambulance on the way to the hospital. This is a major hurdle for machine learning models that typically require large amounts of clean, homogeneous data to train on, especially when dealing with complex data formats like videos. But large amounts of good quality echocardiography videos are not readily available online, in contrast to other types of data like animal images or text. Gathering medical data is complicated, sensitive, and often subject to biases.

“Machine learning models don’t generalise very well outside of a certain domain. A shift in the domain can make them fail completely. Our model should therefore be robust to changing environments: different clinicians, hospitals, patients, and so on…”Fabian Laumer, doctoral student in the Information and Science Engineering Group of Professor Buhmann
The main technical difficulty for Fabian and his colleagues, however, comes from the lack of a so-called “ground truth”. This is what computer scientists refer to as the correct or “true” answer to a given input. It is also the target output that the machine learning model should learn and be validated against. In this case this output is the final 3D heart shape.
Classical supervised machine learning models use sets of labelled data to train. For instance, by analysing a large set of images labelled as “cat” or “dog”, the model will learn to recognise a cat in a new dataset containing unlabelled images of cats and dogs. The more images it sees during training, the better it will become at predicting whether a new image corresponds to a cat or not. The challenge Fabian faces is that he doesn’t have labelled output data. “When we do have the input (the echocardiography video),” Fabian points out, “we still don’t have paired input-output data on which to train the model.” The corresponding synthetic 3D heart (the output) for each patient doesn’t exist yet.
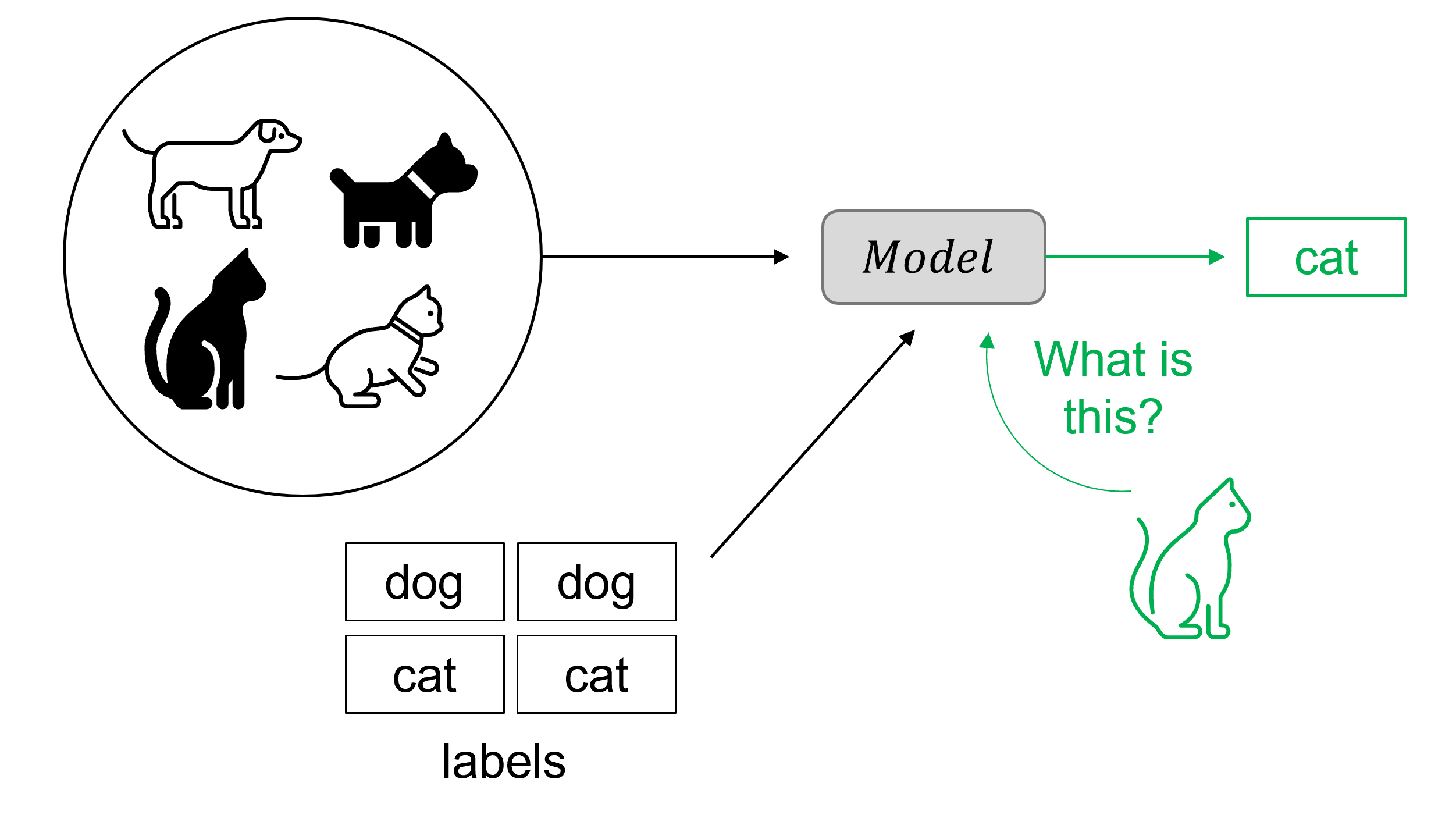
Learning without a ground truth
To circumvent the absence of paired input-output data, Fabian has developed a weakly supervised machine learning model employing a physical prior. He first generated a dataset of 10,000 synthetic 3D heart shapes using a statistical shape model constructed from a pool of CT images from about 20 healthy subjects.
The programme is then trained by racing different parts of the system against each other, in what machine-learning scientists call a “cycleGAN architecture”. One part (in grey in the animation below) is trained to compress the input echocardiography video, decompress it, and then try to reconstruct the initial video. In parallel, a second part (in light blue in the animation below) performs the same operations on the CT-based synthetic heart videos. A discriminator continuously tries to distinguish between outputs that come from an actual patient video and those that come from a synthetic heart. The better the discriminator becomes at distinguishing the origin of the outputs, the better the model becomes at creating them. This competition, together with what is known as “cycle-consistency” (it should be possible to recreate the original video from the generated personalised synthetic heart), leads to a progressive increase in the quality of the generated outputs.
After training, the program generates a synthetic 3D heart that is personalised, because it comes from the patient echocardiography video. It also fits the distribution of 3D heart shapes constructed from CT images, meaning that it looks like what a heart should look like. Once this personalised 3D dynamic shape is generated, the desired clinical variables, such as the ejection fraction or the volume of the ventricles, can simply be extracted.

An additional challenge with the absence of labelled output data is the evaluation of the model. Because it will be used to assist clinical practice, the tool must be highly reliable, and doctors should be able to easily notice if something is incorrect, rather than having to rely on it blindly. It must also be robust and work well enough, however variable the quality of the input video might be. A model that works perfectly on a few very good videos would not be very useful in practice. “Our model needs to be good enough all the time, rather than perfect some of the time,” Fabian summarises. Defining what is good enough in clinical practice is and will remain a challenge.
So far, Fabian and his colleagues have used different strategies to approximate the performance of their model, including comparing the computed left ventricular ejection fractions with those calculated by doctors, which is the current gold standard for this type of measurement. They have also tested it for ten patients where corresponding 3D shapes based on MRI images were available.
A collaborative project with Swiss hospitals
To develop this tool and more refined versions of it, Fabian and his colleagues have joined forces with four university hospitals in Zurich, Bern, Geneva and Basel, as well as with the Swiss Heart Failure Network (SHFN), and collected data from over 3,000 people. Working with medical data and hospitals takes time and is sometimes challenging. But the opportunity to collaborate with doctors and see their work’s potential impact are highly motivating for the team. They meet regularely with clinicians, who are extremely interested and enthusiastic about the technology the team is developing.
Looking two to three years into the future, Fabian hopes to bring the tool into medical practice. Transforming a research project into a clinical application is a lot of work and comes with its own set of challenges, but it can be done reasonably soon, he believes. The software would help clinicians in their practice, initially to create examination reports and eventually also directly assist in making a diagnosis. For patients, this would improve prognosis and reduce the need for invasive clinical evaluations and treatment options.
People who also contributed to the project:
-

Lena Rubi (post-doctoral researcher, Prof. Joachim Buhmann’s lab) is part of the collaboration with SHFN and supports the project with valuable insights and discussion. (Picture: D-INFK) -

Ami Beuret, former software engineer, doctoral student, greatly helped with the implementation of the software to make everything work. (Picture: D-INFK) -

Laura Manduchi (doctoral student, Medical Data Science Group of Prof. Julia Vogt) is part of the collaboration with SHFN and supports the project with valuable insights and discussion. (Picture: D-INFK) -

Alina Dubatovka (doctoral student, J. Buhmann’s lab) is part of the collaboration with SHFN and supports the project with valuable insights and discussion.
(Picture: D-INFK) -

Mounier Amrani supported the project during his master‘s thesis.
(Picture: D-INFK)
-

Dr. Med. Christian M. Matter (Cardiologist USZ) supports the team with valuable insights from a medical perspective. -

Joachim M. Buhmann is Professor and Head of the Information and Science Engineering (ISE) Group at ETH Zurich.
(Picture: Giulia Marthaler)