Students find the answers with AI
How does one find what one is looking for among the numerous publications and research areas of ETH Zurich? To answer this question, ETH staff teamed up with students from the Master’s in Data Science.
Searching for information within the ETH Domain is a mammoth undertaking. Not only does it contain countless websites for departments, units and research groups, all managed independently of each other, but it is also home databases of information such as the Research Collection, a repository for publications and research data containing more than 20,000 papers authored by ETH Zurich’s scientists. How can website visitors successfully search through this wealth of information?
This was the question that Paul Cross, Christine Khammash and Christian Schär asked themselves. Cross works in Institutional Research, Khammash is part of the Corporate Communications web team and Schär is in the Software Services section of ETH’s IT Services. Together, they were tasked with rethinking the search functionality as part of an overall project to improve the university’s website.
It was not an easy task. “Our content and databases are very decentralised,” explains Khammash. “It is a challenge to deliver search results close to what the user expects.” Cross, who has a background in data management, suggested using data science and machine learning to help unify the vast body of disjointed information. “We wanted to explore how we could make the information more accessible using artificial intelligence – and what better place to find expertise than among ETH Zurich’s own researchers,” he says.

The team found the right experts for the job in one of the classrooms of the Department of Computer Science: the Data Science Master’s students Daniel Garellick, Giulia Lanzillotta and Andreas Opedal. They took on the project as part of the Data Science Lab, a course in which future data scientists work on a real-world data science problem from industry, academia or the public sector. From the various projects on offer in the Autumn Semester of 2020, the AI search project caught the three students’ attention as it combined several areas of their interest, from big data to machine learning and natural language processing. “It was also nice to contribute to ETH!” smiles Opedal.
The pitfalls of topic modelling
A central issue with the search function is the conceptual gap between the information on the ETH Zurich website and the queries typed into the search bar by website visitors. “In order to bridge this gap, we used topic modelling and embeddings to add an additional layer between the data and the search query. This layer captures the concepts in that information and groups it based on those concepts,” says Lanzillotta. Thus, when searching for a research area – for example, machine learning – the system returns a list of the most relevant publications in this area, identifies ETH experts in the field and even suggests related research areas, such as artificial intelligence. Typing the name of a professor displays to which department or group they belong, their most recent publications and with whom they most often collaborate – information the current search is unable to provide.
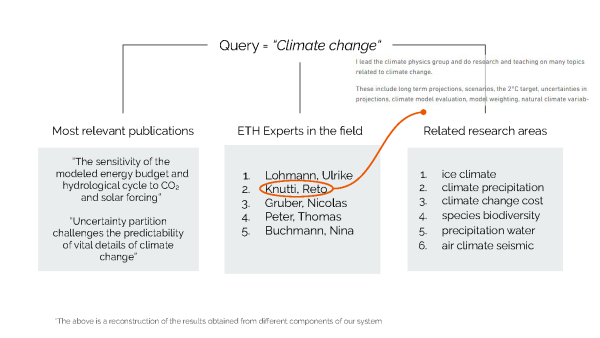
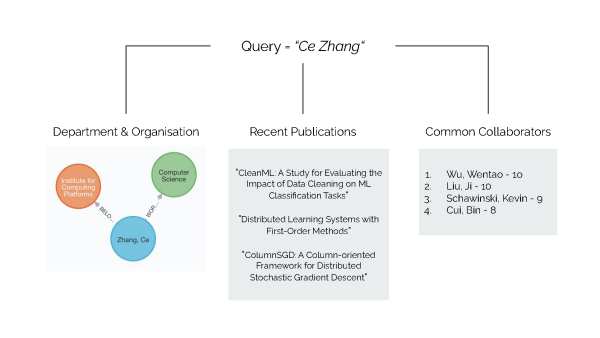
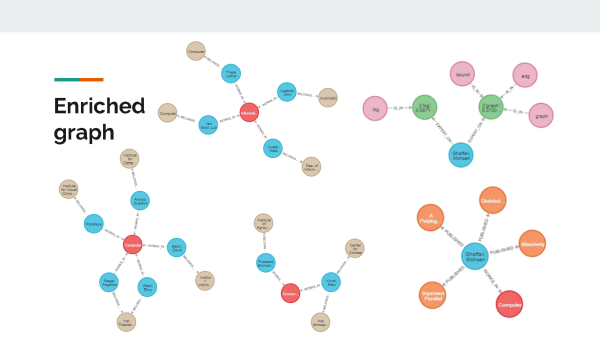
The students achieved their results through a clever combination of several data science and machine learning techniques. First, they used a technique called topic modelling to automatically extract topics from the abstracts of publications in the Research Collection. “If, for example, a paper deals with climate change, our model would identify that,” explains Garellick. The output from this model was put inside a graph database, which displays connections within the information; for example, linking researchers to their research areas, their published papers and their department or group. The students then employed a tool called embedding space to represent all the papers, people, topics and other entities as vectors; this makes the information easy to process and perform operations on, such as a mathematical comparison of different papers.
One model, the embedded topic model, posed a particular challenge for the trio during the initial experimental phase of the project. “We had really pinned our hopes on it, but it just kept failing,” recalls Lanzillotta. “At one point, it would somehow extract violence-related topics from the Research Collection. It was very discouraging.” But this setback eventually steered the students on to the right path. “It forced us to approach the problem from a different angle and use a combination of elements from different areas of data science instead of a single topic model,” explains Garellick. Opedal adds: “We realised it doesn’t matter how complex a model is or how many cutting-edge features it has – if it doesn’t work, don’t use it.”
“We realised it doesn’t matter how complex a model is or how many cutting-edge features it has – if it doesn’t work, don’t use it.”Andreas Opedal, Data Science Master's student
The second-year Master’s students felt well equipped to tackle such challenges. “We had good foundational knowledge, but also the opportunity to learn more,” says Opedal. “We also gained useful soft skills, such as extracting information from papers and evaluating the relevance of the different models to our goals,” adds Garellick. All three have different engineering backgrounds – Lanzillotta is a computer scientist and engineer, Opedal studied industrial engineering and management, and Garellick comes from mechanical engineering – and were friends before the project, allowing them to work together efficiently. “We fitted together like pieces of a puzzle,” says Opedal. Their previous experience gained from internships and jobs also meant they were familiar with real-world project work.
Students as consultants
The efficiency and expertise of the student team did not go unnoticed by the project leaders. “The students not only brought a lot of data science expertise and new ideas to the project, they also behaved as professional consultants,” says Cross. “I was particularly impressed that they used a list of our priorities from the pitch presentation to keep on track throughout the project.” For Khammash it was the first time working with students, but certainly not the last. “They were professional, knowledgeable and focused, and they needed hardly any guidance from us,” she says. “It would be a waste not to tap into this resource in the future.”
Khammash and Cross also valued the assistance of Professor Ce Zhang from the Data Science Lab, who acted as an advisor to both the project leaders and the students. “The search project is well suited to the Data Science Lab, since it has its roots in an emerging real-world problem,” says Zhang, who leads the Data Sciences, Data Systems, and Data Services (DS3Lab) research group at the Department of Computer Science. “We are always impressed by how well the students perform in this course, and this search project is no exception.”
“The students were professional, knowledgeable and focused, and they needed hardly any guidance from us. It would be a waste not to tap into this resource in the future.”Christine Khammash, Corporate Communications
Opedal, Lanzillotta and Garellick in turn appreciated the guidance from both Zhang and the project leaders, as well as that from Tarun Chadha, data scientist with the Scientific IT Services, who assisted the project team. The broad scope of the project allowed the students to be inventive, with the freedom to choose their approach. “But Paul, Christine and Tarun guided us in the right direction and pulled us back to earth when we needed it,” says Garellick.
Due to the exploratory nature of the students’ work, it will be a while yet before artificial intelligence helps users to find what they need on the ETH website. “I’m somewhat relieved,” admits Lanzillotta. “I would feel responsible for every single search otherwise!” However, the project team plans to pursue the students’ ideas further, and perhaps more projects with the Data Science Lab. “Although making the right type and quality of data available to the students is a lot of work, we would highly recommend participating in a Data Science Lab project to colleagues across ETH Zurich and beyond,” says Cross. “It’s an effective and rewarding way to explore real-world challenges with motivated, capable and professional data science experts.”
Master’s programme in Data Science

Computers have fundamentally changed the way we produce, manage, process and analyse data. In light of the continuous growth of data all around the globe, the question of how we can use it to gain valuable insights is more important than ever. How can relevant information be extracted from the massive amounts of data generated on a daily basis? In which ways can computers learn from experience to make intelligent decisions? These questions are key to the specialised data science Master’s programme, which is jointly run by the Departments of Mathematics (D-MATH), Information Technology and Electrical Engineering (D-ITET), and Computer Science (D-INFK) at ETH Zurich.